pythonでwebスクレイピングする。
最終目標はMGSの新着動画ページ(https://www.mgstage.com/search/cSearch.php?search_word=&sort=new&list_cnt=30&range=latest&type=top)をスクレイピングしようと思う。
まずスクレイピングの基礎から。
python3でwebスクレイピング(Beautiful Soup)(https://qiita.com/mtskhs/items/edf7dbba9b0b0246ef8f)
を参考にこのサイトをスクレイピングしてみる。
1 2 3 4 5 6 | import requestsfrom bs4 import BeautifulSoupresponse = requests.get(url)soup = BeautifulSoup(response.content, 'lxml')print(soup) |
これで、このサイトの「doctype html」から「/html」までの全てのソースコートが取得できる。
find~を指定すると取得する値をタグ等で指定できる。
1 2 3 4 | # タグで取得print (soup.find_all("h1"))print (soup.find_all("a"))print (soup.find_all("img")) |
クッションページを回避してスクレイピング
MGSは年齢認証のクッションページがあるため、上記のコードではクッションページのスクレイピングをしてしまう。
Pythonで年齢認証などのクッションページを回避してスクレイピングしたい(https://qiita.com/aizakku_nidaa/items/71829aa111be68843b8b)
を参考にやってみる。
どうやらクッキーを渡せば良いらしい。
クッキーは【Chrome】Cookieを確認する方法(https://coeure.co.jp/blog/pc_support/chrome_cookie_180208)で調べる。
クッキー消したりして年齢認証のクッキーを特定↓
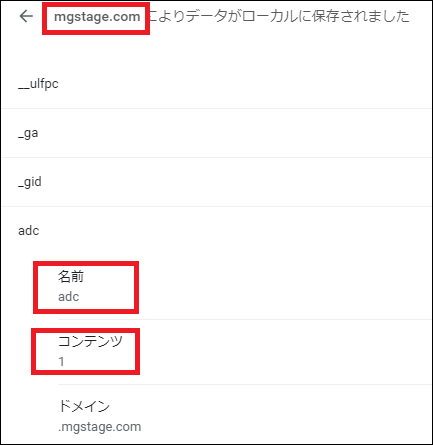
参考サイトと同じクッキーだった。
書いた人もMGSのスクレイピングしてたのだろうか。
1 2 3 4 5 6 | import requestsfrom bs4 import BeautifulSoupurl = 'https://www.mgstage.com/search/cSearch.php?search_word=&sort=new&list_cnt=30&range=latest&type=top'cookie = {'adc': '1'} # 名前:コンテンツsoup = BeautifulSoup(requests.get(url, cookies=cookie).content, 'lxml')print(soup) |
xmlに書き込む
取得できたのでxmlにする。
①BeautifulSoupで値を取得
②ループ処理
③XMLファイルへの書き込み
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import requestsfrom bs4 import BeautifulSoupimport datetimedt_now = datetime.datetime.now()print(dt_now)url = 'https://www.mgstage.com/search/cSearch.php?search_word=&sort=new&list_cnt=30&range=latest&type=top'cookie = {'adc':'1'} #名前:コンテンツsoup = BeautifulSoup(requests.get(url, cookies=cookie).content, 'lxml')rank_list = soup.find('div', class_="rank_list") #soupからrank_listのみ指定rank_list_li = rank_list.find_all('li') #rank_listから全てのliを指定item_xml = '' #not definedエラー避けfor oisii_soup in rank_list_li: #for 変数名 in 繰り返し条件:→「rank_list_li」の数だけ繰り返し処理 title = oisii_soup.find('p', class_="title lineclamp") #タイトル取得 title = title.get_text() #テキストのみ title = title.replace('&', '&')#XML用エスケープ print(title) img = oisii_soup.h5.img['src'] #画像URL取得 print(img) href = oisii_soup.h5.a['href'] #リンクURL取得 print(link) item_xml_temp = " <item>\n <title>"+title+"</title>\n <link>"+link+"</link>\n <pubDate>2020-11-22T12:07:00+09:00</pubDate>\n <description><![CDATA[<a href='"+link+"'><img src='"+img+"'></a>]]></description>\n </item>\n\n" item_xml = item_xml + item_xml_tempbefore_xml = "<?xml version='1.0' encoding='UTF-8' ?>\n<rss version='2.0'>\n<channel>\n <title>MGS新着動画のRSSフィード</title>\n <link>https://www.mgstage.com</link>\n <description>MGS新着動画のRSSフィード</description>\n <lastBuildDate>2020-11-22T12:36:02+09:00</lastBuildDate>\n <language>ja</language>\n"after_xml = '</channel>\n</rss>'merge_xml = before_xml+item_xml+after_xmlf = open('test.xml','w') #出力(w=上書き/a=追記)f.write(merge_xml)f.close() |
レンタルサーバーで動かす
……挫折。
スターサーバーで動かそうとしたけど、上手く行かなかった。
やはりWEBサイトに出力するならPHPの方が使いやすいか。
PHPでwebスクレイピング
pythonに挫折した僕はPHPでスクレイピングする。
別にそこまでMGSの情報が欲しいわけでもなかったのだけど。
使い慣れた「simple_html_dom」使う。処理が重たい以外の欠点がない。
というか処理が重いからPython使ってみたかったところもあるが。
ともかく、クッキー渡したことないのでそこをやる。
スクレイピングをしてみよう 認証・リダイレクト回避編(http://www.lesson5.info/?p=203)を参考に進める。
内容は理解してないけど、書いてある通りやって解決↓
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <?phpinclude __DIR__."/function/simple_html_dom.php";$item_url = 'https://www.mgstage.com/search/cSearch.php?search_word=&sort=new&list_cnt=30&range=latest&type=top';$opts = array('http'=>array('method' => 'GET','header' =>"Referer: https://www.mgstage.com\r\n". // リファラーをセット"Cookie: adc=1\r\n") );// 認証のクッキーの名前が「adc」で値が「1」$context = stream_context_create($opts);$html = file_get_html($item_url, false, $context);foreach ($html->find('div') as $entry) {echo $entry;}?> |
あとはなんやかんやしてXMLに出力。
レンサバのCRON設定で1日1日くらい更新させておく。
エクセルとかに出力して分析するとかならPythonが便利そうではあるけど、レンサバでただただ情報を自動更新させときたいならPHPの方が良い気がする。
というかレンサバ=ウェブサイト=PHPの相性が良い。