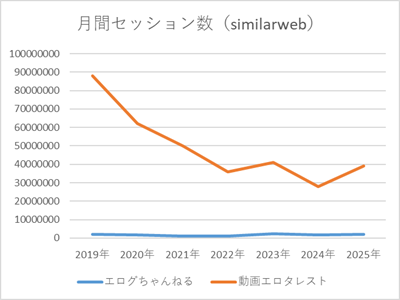
このサイトは「旧スタードメイン契約特典 PHP+MySQLサーバー」で運営してたけど、来年の3月まででサービス終了するらしい。
「旧スタードメイン契約特典 PHP+MySQLサーバー」は2022年3月31日(木) 正午をもって提供を終了します。
ということでサーバー移転する。
WPの標準エクスポート+インポート機能を使う。
エクスポート
下のボタンをクリックすると、WordPress がローカルに保存するための XML ファイルを作成します。
WordPress eXtended RSS もしくは WXR と呼んでいるこのフォーマットには、投稿、固定ページ、コメント、カスタムフィールド、カテゴリー、タグが含まれます。
ファイルをダウンロードして保存すると、別の WordPress インストールにこのサイトのコンテンツをインポートできます。
移行先のサーバー設定とか、ドメインのDNS設定とかしてからインポート実行。
インポーターの実行
WordPress エクスポートファイルから投稿、ページ、コメント、カスタムフィールド、カテゴリー、タグをインポートします。
実行結果……「メディアのインポートに失敗しました」
記事はインポートできた。ただしメディアがない。というかそもそもメディアエクスポートしてない気がする。
よくよく思い返すとエクスポートが一瞬で終わってたし文字だけだろう。
ググるとメディアも一緒に移転できるプラグインもあるっぽいけど、写真は手動で旧サーバーのWPのメディアフォルダーを新サーバーのメディアフォルダーにコピペする。
テーマとか、ウィジットとか、プラグインとか、再設定して、移転完了。
画像の移転に時間かかった。山の写真ででかい。次からもっと小さくしようと決意する。
サイズもだけどWordPress画像の自動生成ほんとやめてほしい。
テンプレート変えたタイミングで消し忘れてたことに今更気づく。
WordPress画像の自動生成を停止する方法(https://hebochans.com/stop-auto-generate-imgs/)
あと改行も消えてるっぽい。
あとついでにSSL化したのだけど、1016年以前くらいのアマゾンの画像が、Chromeで見ると表示されないのムカつく。
グーグルさん非SSL嫌いすぎ。